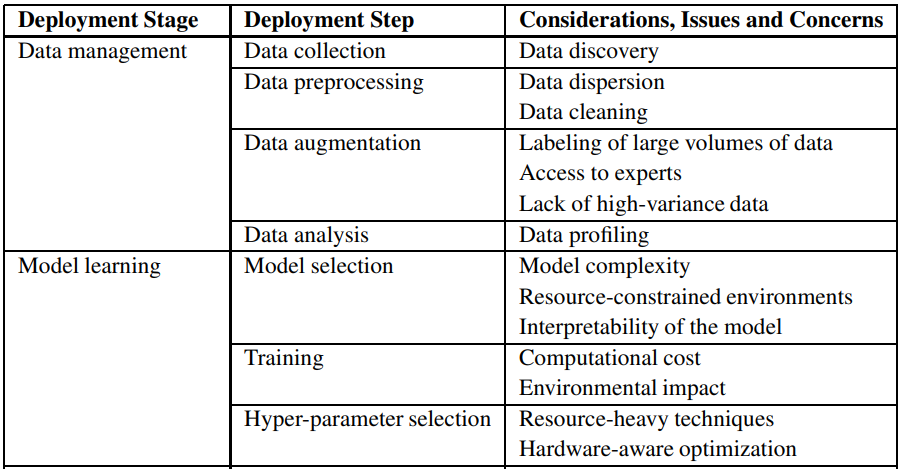
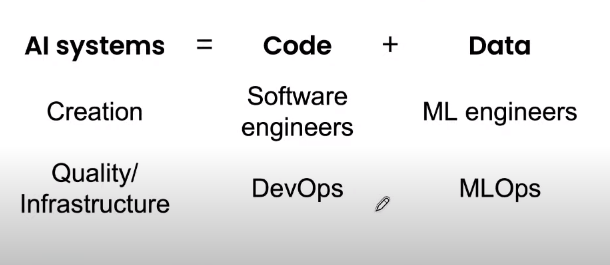
In practice, there are many different scenarios that can facilitate or hinder the deployment of AI systems. For example, a network company has a software that collects data from many users, creating a large dataset for training. This is a favorable initial condition for developing a machine learning model. However, in another environment such as agriculture or healthcare, where there are not enough data samples, we cannot expect to have a million tractors or a million patients to help increase the amount of data collected! Therefore, Andrew Ng directs the community’s attention to MLOps – a field that focuses on building and deploying machine learning models according to a standardized process. Some basic rules that Andrew Ng proposed to help deploy machine learning effectively:
The most important task of MLOps is to provide high-quality data.
Consistency in data sample labels is key. For example, check how labelers use bounding boxes. There may be multiple ways to label, and even if they are good in their own right, inconsistencies can ruin the results.
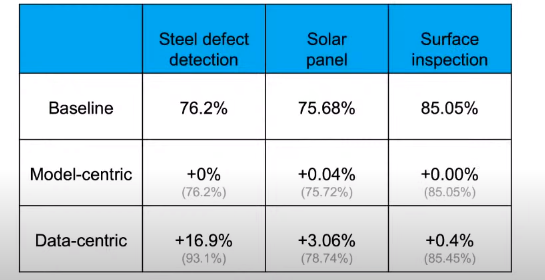
Systematically improving data quality on a baseline model is better than running a state-of-the-art model on low-quality data.
In case of errors during training, take a data-centric approach.
By focusing on the data, problems with smaller datasets (less than 10,000 samples) can be significantly improved.
When working with smaller datasets, tools and services to improve data quality are crucial.
“If 80% of our work is data preparation, then data quality assurance is the most important part of the ML development team,” says Andrew. Good data should be consistent, include all the special cases, have timely feedback from data production, and be appropriately sized. He advises against relying solely on engineers to figure out the best way to improve datasets. Instead, he hopes the machine learning community will develop MLOps tools that help create high-quality, repeatable, and systematic datasets and AI systems. He also says that MLOps is a new field; in the future, the most important goal of MLOps development teams should be to ensure a consistent, high-quality data flow across all stages of the project.
Source:
![]() Big Data To Good Data: Andrew Ng Urges ML Community To Be More Data-Centric And Less Model-Centric
Big Data To Good Data: Andrew Ng Urges ML Community To Be More Data-Centric And Less Model-Centric