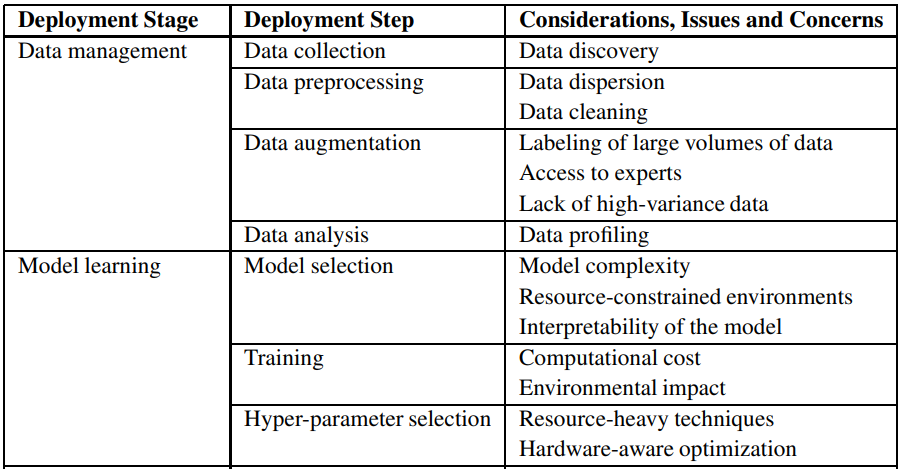
Trong thực tế, có nhiều trường hợp khác nhau có thể thúc đẩy hoặc cản trở quá trình triển khai hệ thống trí tuệ nhân tạo. Ví dụ, một công ty mạng có một phần mềm thu thập dữ liệu của nhiều người dùng tạo ra một bộ dữ liệu gồm nhiều mẫu để huấn luyện. Đó là điều kiện thuận lợi ban đầu để phát triển mô hình học máy. Tuy nhiên, trong một môi trường khác chẳng hạn như nông nghiệp hoặc chăm sóc sức khỏe, nơi không có đủ mẫu dữ liệu, chúng ta không thể mong đợi có một triệu máy kéo hoặc một triệu bệnh nhân để giúp tăng lượng dữ liệu thu thập! Vì thế, Andrew Ng hướng sự chú ý của cộng đồng tới MLOps – một lĩnh vực tập trung xây dựng và triển khai các mô hình học máy theo một quy trình được chuẩn hóa. Một vài quy tắc cơ bản mà Andrew Ng đã đề xuất để giúp triển khai học máy một cách hiệu quả:
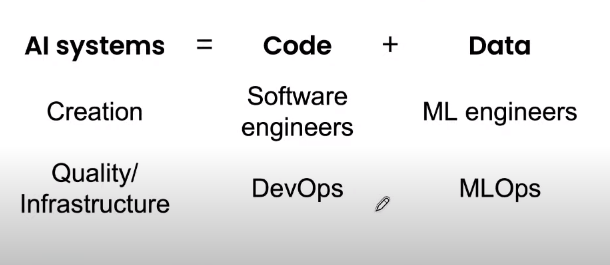
Nhiệm vụ quan trọng nhất của MLOps là cung cấp dữ liệu chất lượng cao.
Tính nhất quán của nhãn mẫu dữ liệu là yếu tố then chốt. Ví dụ: kiểm tra cách người gắn nhãn sử dụng các hộp giới hạn (bounding box). Có thể có nhiều cách ghi nhãn, và ngay cả khi chúng tốt theo cách riêng của chúng, nhưng việc thiếu nhất quán có thể làm xấu kết quả.
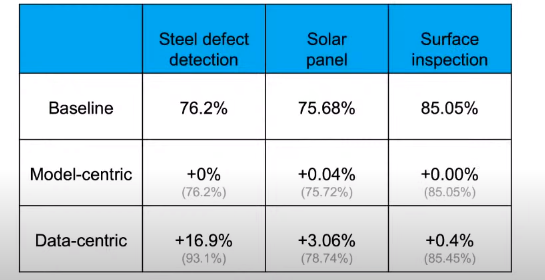
Cải thiện chất lượng dữ liệu có hệ thống trên mô hình cơ bản tốt hơn là chạy theo mô hình hiện đại với dữ liệu chất lượng thấp.
Trong trường hợp có lỗi trong quá trình huấn luyện, hãy áp dụng cách tiếp cận lấy dữ liệu làm trung tâm.
Với việc tập trung vào dữ liệu, có thể cải thiện đáng kể các vấn đề với tập dữ liệu nhỏ hơn (ít hơn 10000 mẫu).
Khi làm việc với các bộ dữ liệu nhỏ hơn, các công cụ và dịch vụ để nâng cao chất lượng dữ liệu là rất quan trọng.
Andrew nói “Nếu 80% công việc của chúng ta là chuẩn bị dữ liệu, thì đảm bảo chất lượng dữ liệu là phần việc quan trọng bậc nhất của nhóm phát triển học máy”. Một dữ liệu tốt phải có tính nhất quán, bao gồm toàn bộ các trường hợp đặc biệt, có phản hồi kịp thời từ khâu sản xuất dữ liệu và xác định kích thước phù hợp. Ông khuyên không nên chỉ dựa vào các kỹ sư để có cơ hội tìm ra cách tốt nhất để cải thiện tập dữ liệu. Thay vào đó, ông hy vọng cộng đồng học máy sẽ phát triển các công cụ MLOps giúp tạo ra các bộ dữ liệu và hệ thống thông minh nhân tạo chất lượng cao, có thể lặp lại và có hệ thống. Ông cũng cho biết MLOps là một lĩnh vực mới; trong tương lai, mục tiêu quan trọng nhất của các nhóm phát triển MLOps phải là đảm bảo luồng dữ liệu chất lượng cao và nhất quán trong tất cả các giai đoạn của dự án.
Nguồn:
![]() Big Data To Good Data: Andrew Ng Urges ML Community To Be More Data-Centric And Less Model-Centric
Big Data To Good Data: Andrew Ng Urges ML Community To Be More Data-Centric And Less Model-Centric